Disclosure: This post may contain affiliate links. If you purchase through our links, we may earn a commission at no extra cost to you. We only recommend tools and services J. Massey's team actually uses.
Learn more →
I've sat across the table from operators at every stage. The ones who stalled at three properties. The ones who hit ten and kept building. The ones who thought they wanted to scale and discovered they didn't.
The difference isn't capital. It isn't market timing. It isn't even operational skill at the start.
I've spent 15+ years in this space, trained more than 10,000 operators through CashFlowDiary, and recorded 237+ podcast episodes breaking down the deals that work and the ones that don't. The pattern below shows up in every cycle.
It's how they metabolize failure.
The 2 AM Fire Alarm Test
The fire alarm goes off at 2 AM. Guest calls. Panicked. You walk them through resetting it. You apologize. You send a bottle of wine in the morning. The review still comes back three stars.
Here's where operators split into two populations.
The ones who stall internalize it. They replay the event looking for the character flaw. "I should've checked the battery." "I'm not detail-oriented enough." "Maybe I'm not cut out for this." The failure becomes evidence about who they are.
The ones who scale externalize it. They see an event that produced data. "The battery check isn't in the turnover checklist." "We don't have a backup protocol for middle-of-the-night maintenance calls." "The wine gesture is reactive — what's the proactive move?" The failure becomes a systems diagnostic.
Same fire alarm. Same three-star review. Completely different cognitive load.
The operator who internalized it carries that weight into property four, five, six. Every new problem confirms the narrative. They're working harder to prove they're capable instead of building systems that make capability irrelevant.
The operator who externalized it ships a checklist update Monday morning. Adds a battery replacement schedule. Builds a middle-of-the-night protocol with the property manager. Three months later, the same failure mode doesn't exist anymore.
The Pattern Shows Up at Every Stage
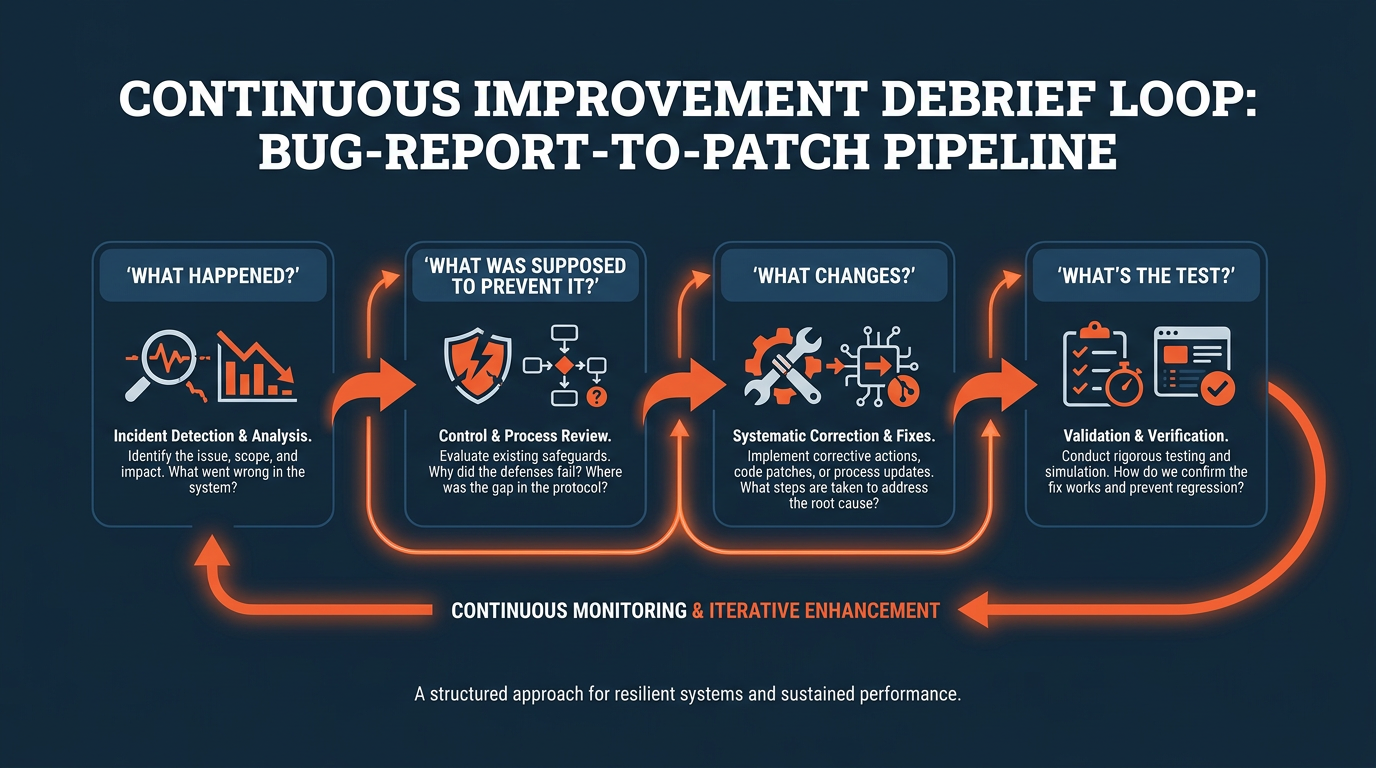
Four-step debrief loop: what happened, what prevents it, what changes, what's the test
This isn't a mindset issue. It's a structural misdiagnosis that compounds.
At property three, you blame yourself for the breakdown instead of building the system that prevents it. At property seven, you're still the bottleneck because you never trusted a system to carry what you thought only you could handle. At property ten, you're exhausted and convinced scaling was the mistake — when the actual mistake was running ten properties out of your head instead of building the operational architecture that lets ten properties run themselves.
I've watched this pattern across hundreds of operators. The ones who scale don't have thicker skin. They don't "handle stress better." They just have a different relationship with what a failure means.
A failure is an event. It's not a person.
"The operators who stall treat failure like a referendum on their worth. The ones who scale treat it like a bug report: something broke, here's the patch, here's how we verify it shipped."
— J. Massey · CashFlowDiary
When you treat failure as an event, you can study it. You can extract the variable that broke. You can test a fix. You can verify the fix worked. Then you move to the next thing.
When you treat failure as evidence about yourself, you can't study it cleanly. The data is contaminated with identity. You're defending, justifying, or trying to outwork the conclusion instead of just fixing the system and moving on.
The Operators Who Scale Don't Skip the Debrief
Here's what the operators who made it past ten properties do that the stalled operators don't:
They debrief every failure the same way. No moral weight. No character analysis. Just structure.
What happened? Name the event. Guest called at 2 AM. Fire alarm. Three-star review.
What was supposed to prevent it? Battery check during turnover. If that check existed, did it fail? If it didn't exist, why not?
What changes? Add battery replacement to the turnover checklist. Set a quarterly battery audit across all properties. Build a middle-of-the-night protocol so the guest gets a response in under five minutes without you waking up.
What's the test? Run the new checklist for 90 days. Track how many fire alarm calls happen. If the number drops, the system works. If it doesn't, diagnose again.
That's it. Four questions. No therapy. No identity work. Just operational triage.
The operators who stall skip the debrief or turn it into a referendum on whether they're good enough. The operators who scale treat it like a bug report. Something broke. Here's the patch. Here's how we verify it shipped.
The Same Misdiagnosis Shows Up in Revenue Departments
This pattern — mistaking an operational issue for a character issue — doesn't just show up in how operators handle failure. It shows up in how they structure their businesses.
Most operators I work with view the customer experience department as an expense. It's the team that handles guest complaints, responds to reviews, and smooths over problems. The budget conversation is always: "How little can we spend here?"
That's the same misdiagnosis.
Customer experience isn't an expense department. It's a revenue-generating department.
Here's what actually happens when you staff it correctly:
Claims collections. When something breaks — HVAC, plumbing, appliance failure — your customer experience team documents it, files the claim with your insurance or the property owner, and recovers the cost. I've seen operators recover $15K–$40K annually per property just by having someone who knows how to work the claims process instead of eating the cost.
Upsells. Early check-in requests. Late check-out requests. Extra cleaning mid-stay. Grocery stocking before arrival. Every one of those is a revenue event if someone's trained to offer it and process it. Operators who treat customer experience as reactive support leave $8K–$12K per property on the table every year.
Cross-sells. Guest books property A for a weekend. Loved it. Customer experience team follows up two months later: "We just launched property B in the same area — would you like first access to the calendar?" That's not marketing. That's relationship infrastructure converting into repeat bookings.
Review conversion. Better reviews mean better search ranking, higher booking rates, and the ability to charge more. A five-star property books 30–40% more often than a 4.3-star property in the same market. Customer experience is the department that moves that number. If you're treating it as an expense, you're missing the compounding return.
The operators who scale past ten properties don't view customer experience as the team that cleans up problems. They view it as the team that generates cash flow through operational intelligence.
Same department. Completely different financial outcome depending on how you diagnose its function.
The Cognitive Load of Misdiagnosis Stacks
Here's what happens when you keep misdiagnosing operational problems as personal failures:
You work harder instead of building systems. You take on more yourself instead of delegating to structure. You treat every breakdown as evidence you're not ready to scale instead of evidence the system needs an upgrade.
The cognitive load compounds. You're carrying the operational weight of ten properties plus the emotional weight of ten properties worth of self-doubt.
The operators who scale don't carry that second load. They're running the same operations, facing the same breakdowns, dealing with the same middle-of-the-night guest calls. But they're not also running an internal trial about whether they're good enough to keep going.
That difference — the absence of that second load — is what creates the capacity to keep building.
What This Looks Like in Practice
A failure tangled into looping self-doubt and cognitive overload
One of the operators I work with hit this wall at property six. Every time something broke, he'd spiral. "I should've seen that coming." "I'm not organized enough." "Maybe I'm growing too fast."
We sat down and ran the debrief structure on his last three failures. Cleaning crew no-showed on a turnover day. Guest complained about WiFi speed. Property manager missed a maintenance request.
None of those failures had anything to do with him. They were all systems gaps.
Cleaning crew no-show? No backup protocol. We built one. Now if the primary crew doesn't confirm by 10 AM on turnover day, the backup crew gets the call automatically.
WiFi complaint? No speed test during property setup. We added it to the onboarding checklist. Every property gets tested at 50+ Mbps before it goes live.
Missed maintenance request? No tracking system. We built a shared board where every request gets logged, assigned, and closed. If something sits open for 48 hours, it escalates automatically.
Three failures. Three systems. Zero character analysis.
Six months later, he's at property eleven. The operations are smoother. The breakdowns are rarer. And when something does break, he doesn't carry it as evidence about himself. He just runs the debrief, patches the system, and moves on.
The Question That Separates the Two Groups
When something goes wrong, the operators who stall ask: "What's wrong with me?"
The operators who scale ask: "What's missing from the system?"
That's the entire difference.
One question traps you in a loop where every failure requires more effort, more discipline, more proof that you're capable.
The other question points you toward the fix: build the checklist, automate the follow-up, delegate the task, test the new process.
Same failure. Same three-star review. Same fire alarm at 2 AM.
Completely different cognitive path depending on which question you ask.
How to Rewire the Pattern
If you recognize yourself in the first group — the operators who internalize failure — here's the path out:
Stop debriefing failures alone. When you're inside your own head, every failure looks like evidence about you. Bring in a peer, a consultant, or a co-founder. Run the four-question debrief structure with someone who isn't emotionally attached to the outcome. They'll see the systems gap you're missing because you're too busy defending yourself to yourself.
Track failure categories, not failure events. Don't keep a list of everything that went wrong. Keep a list of the systems that don't exist yet. "Guest communication breakdown" is a category. "Fire alarm at 2 AM" is an event. Build systems for categories. The events will stop recurring.
Set a 48-hour rule. When something breaks, you have 48 hours to feel however you feel about it. After that, the only question that matters is: what's the system fix? This isn't about suppressing emotion. It's about containing it so it doesn't contaminate the debrief.
Treat your customer experience team as revenue infrastructure. If you're currently budgeting customer experience as an expense, reframe it. Calculate what claims recovery, upsells, cross-sells, and review conversion are worth annually. Then staff and train the team to hit those numbers. You'll see the ROI inside 90 days.
The Operators Who Scale Built Different Cognitive Architecture
A failure flowing cleanly through diagnose, patch, verify to a checkmark
This isn't about resilience. It's not about grit. It's not about "handling stress better."
The operators who scale past ten properties built a different cognitive architecture. They separated the event from the identity. They built systems instead of trying harder. They treated failure as operational data instead of personal verdict.
The work is the same. The properties are the same. The breakdowns are the same.
What's different is the question they ask when something breaks — and that question determines whether they build the system that prevents it from breaking again or just carry the weight of it into property eleven, twelve, thirteen until the whole operation collapses under cognitive load that was never structural in the first place.
You don't scale by being better at handling failure. You scale by building systems that make most failures irrelevant — and treating the ones that slip through as diagnostics, not verdicts.
That's the difference. That's the entire game.
Common Questions About Scaling Past Ten Properties
Why do some operators stall at three properties while others scale past ten?
The ones who stall treat each failure as a referendum on whether they are good enough. The ones who scale treat failure as a bug report: name the event, find what should have prevented it, change the system, and test the fix. Same failures, different cognitive architecture.
What is the four-question failure debrief?
A structured triage for any breakdown: What happened? What was supposed to prevent it? What changes? What is the test? Four questions, no character analysis, just the event, the gap, the patch, and the verification window.
How long should you test a fix before deciding it worked?
Run the new checklist or protocol for about 90 days and track the metric it was meant to move. If the number drops, the system works. If it does not, diagnose again. The test is operational, not emotional.
Why does misdiagnosing failure as a character flaw stall growth?
It stacks cognitive load. Every unresolved failure filed as "I am not good enough" instead of "the system has a gap" consumes attention and compounds. Operators who debrief structurally keep their cognitive architecture clean enough to keep scaling.
Build the Debrief Into Your Operation
The operators who scale past ten properties are not more talented. They run a tighter failure loop. Every breakdown gets the same four-question debrief, a patch, and a verification window. No identity, no drama, just structure. That is the cognitive architecture we install with operators before the portfolio gets big enough to break.
If you want that system mapped to your operation, the debrief cadence, the checklist discipline, the middle-of-the-night protocols, that is what we work through on a strategy call.
Earnings & Income Disclaimer: West Egg Enterprises, Inc. / CashFlowDiary does not guarantee any specific income, profit, or financial results from information on this site. Individual results vary based on effort, experience, market conditions, and other factors outside our control. Past performance does not guarantee future results. Nothing on this site constitutes financial, legal, or tax advice.